
Exactly one year ago, Jeremy Howard published a proposal to make the web more accessible to AI and, in particular, to LLMs. How many of the top one million websites adopt this approach?
The proposed standard suggests creating a file at the root of a website, e.g., /llms.txt,
intended to be consumed by LLMs and AI tools, loosely taking inspiration from /robots.txt.
The /llms.txt serves as an entry point or site map of the website, potentially linking to other pages.
As the source code of a webpage is often very verbose and its content is mingled with style sheets, JavaScript, and HTML markup,
parsing the source with an LLM might exceed the LLM’s content window or consume too many tokens.
Therefore, the idea is to use Markdown for the /llms.txt entry point and to link to Markdown versions of each page.
How many websites adopted this approach?
Let’s measure.
Starting with a dataset of the 10 million highest-ranked domains
from Open Page Rank,
we can send a GET request to /llms.txt for each of them and see how many web servers respond with an HTTP success code.
It turns out, a lot of web servers respond with a 200 status code but actually send a
page informing the client that the page doesn’t exist.
For example, the top-ranked domain, facebook.com, behaves in that way.
A GET request to https://facebook.com/llms.txt returns a 200 status code, but the pages says the content is not available.
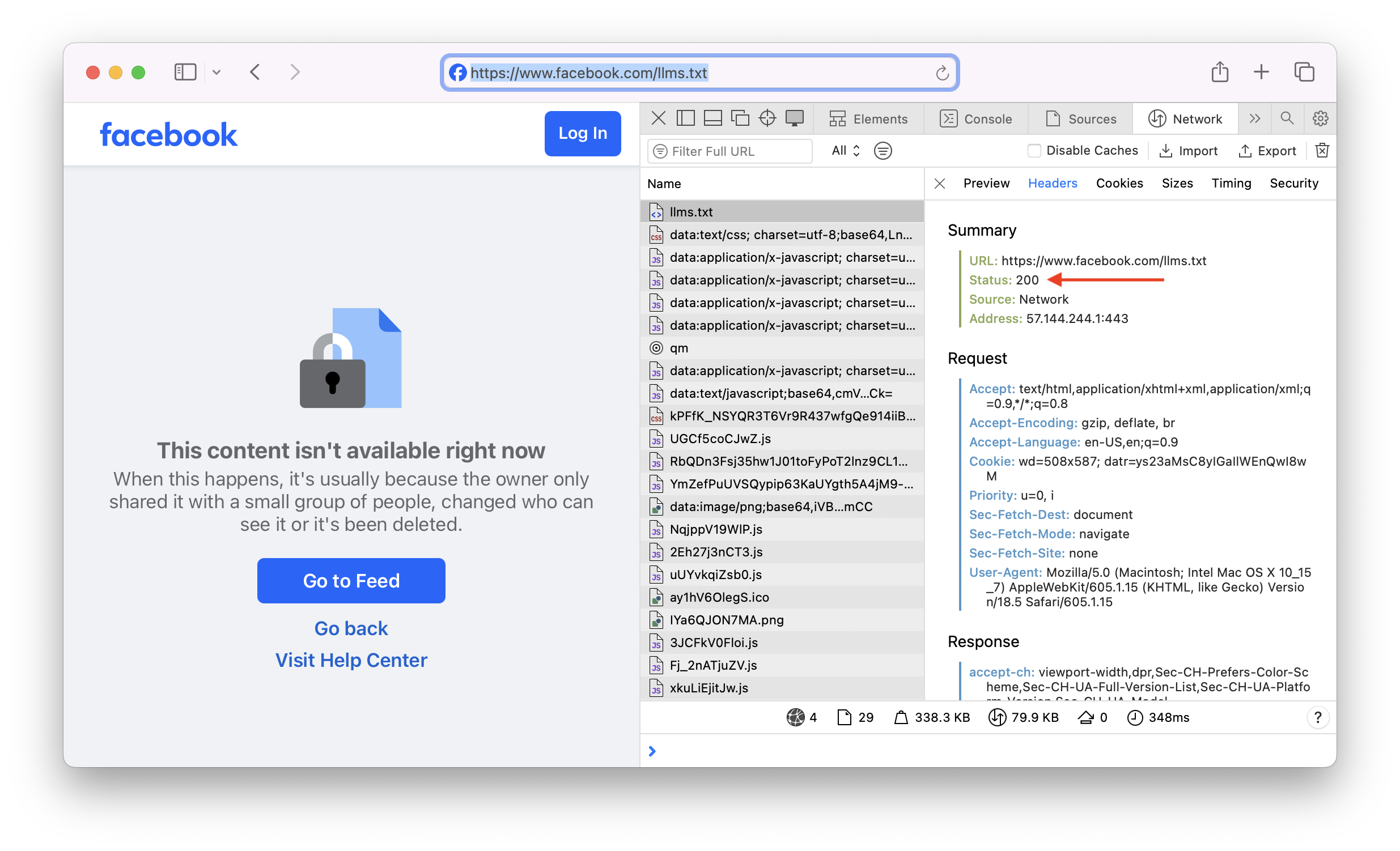
A typical feature of these fake-success responses is that the response page is an HTML document.
However, sometimes the Content-Type header field is not a reliable discriminator to detect fake-success pages.
A good way to distinguish HTML content from Markdown is to compare the number of occurrences of the left angle bracket (<) character to the
left square bracket ([).
The first is ubiquitous in HTML, while the latter is common in Markdown.
I came up with the following somewhat arbitrary rules. Only if a response satisfies all of them, I count it as a valid /llms.txt response.
- HTTP response code must be less than 400
- Content-Type header must start with
text/plain - The web server must accept the connection within 3 seconds
- The response must arrive within 10 seconds
- The site must support HTTPS
- The response content must be longer than 500 chars
- There must be more left square brackets than left angle brackets
To speed up the analysis, it limited it to the top one million domains. I ran the analysis on September 2, 2025.
Results
Domains ranked high in the domain ranking might be faster to adopt new technological ideas.
To test this, I counted the fraction of domains with /llms.txt among the top n domains.
The result is shown in the following chart.
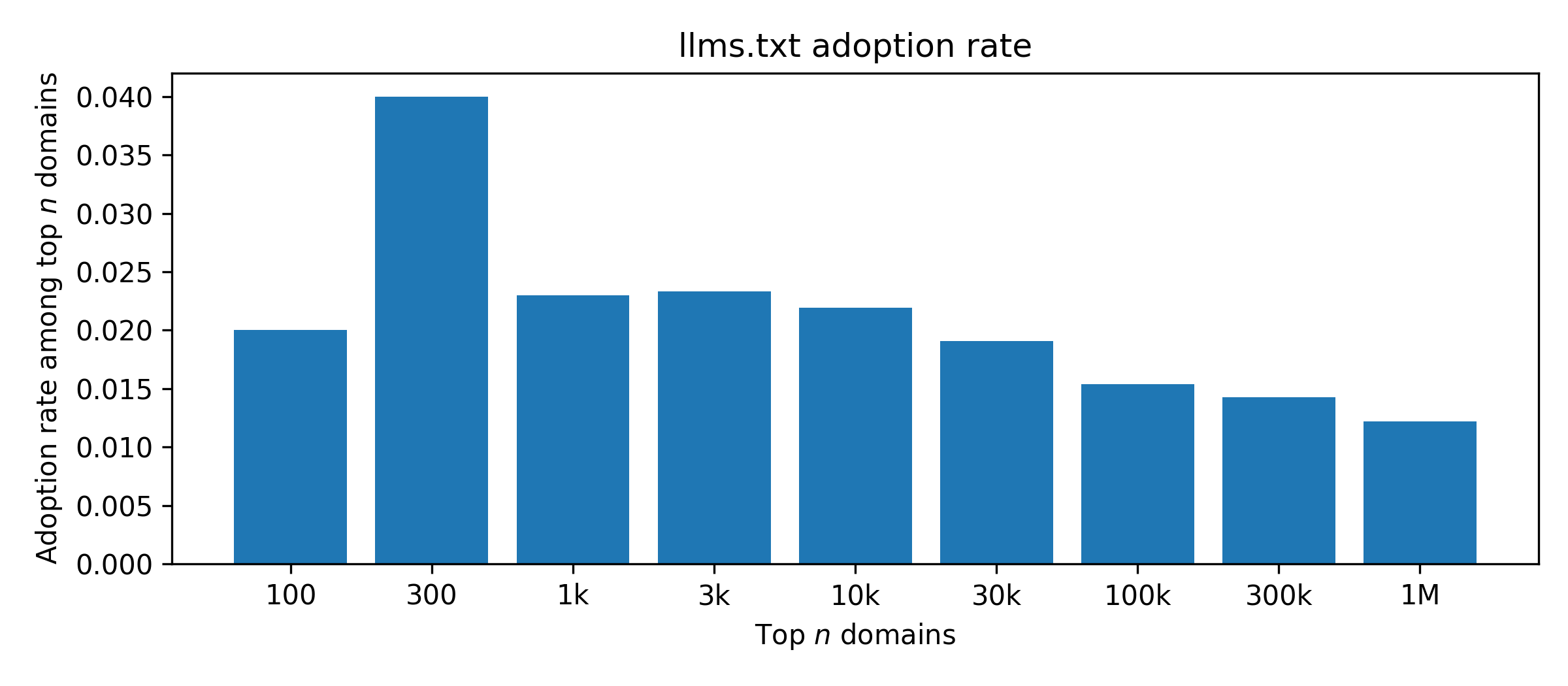
Based on these results, we see that the largest adoption rate at 4 % is among the top 300 domains. The fraction continuously decreases further down the ranking. Looking at the top one million domains, we see that the overall adoption rate drops to around 1.2 %. In total, that corresponds to 12174 domains.
The crawler, the analysis code, and the result dataset are available in a Git repository.
This might also interest you