
Technical innovations often offer numerous applications with tremendous added value, making work easier. However, this also increases the potential for misuse, with the opposite effect—whether deliberately or through improper use. This also applies to advances in the field of Artificial Intelligence (AI). The aim of this article is to shed light on how current text-based AI applications work, so that they can be used meaningfully and appropriately in the field of safety science. The focus here is not to discourage their use, but to encourage an active discussion about sensible applications and their adoption.
From a user’s perspective, lack of understanding of how AI applications work creates several obstacles. In the following, I will focus on text-based applications powered by Large Language Models (LLMs). Since the launch of ChatGPT in November 2022, it took only a few months before insufficient understanding during use made headlines. As various media reported, a lawyer in New York used ChatGPT to research legal precedents, which he then submitted to the court. It later emerged that most of the cases presented by ChatGPT were either incorrectly cited or completely made up. This behavior, known among experts as “hallucination,” is a characteristic of LLMs. The lawyer claimed to have acted under the assumption that ChatGPT was a search engine. The legal consequences in this case led to the lawyer being fined. Numerous reports of similar cases have emerged over the past two years.
The example above illustrates how important it is to understand how AI applications work. This is not limited to ChatGPT and can also be transferred to other AI tools. Below, I describe how language models function and how modern AI tools are derived from them.
Large Language Models
Large Language Models are neural networks, that is, in a broad sense, nonlinear mathematical functions that compute an output from an input. In the case of language models, both the input and output are text. LLMs are used in almost all generative, text-based AI services. However, they are often hidden behind several layers of application-specific logic. The foundation for today’s models was laid by Google employees in 2017 with the Transformer architecture and the so-called Attention mechanism.
The term “Large” in Large Language Models refers to the number of parameters and the associated memory requirement. There is no clear cutoff to define the term and it is expected that the development of ever larger language models will continue. If the language model is viewed as a mathematical function, the number of parameters becomes comparable: A first-degree polynomial, i.e. a function that describes a straight line in a plane, has two parameters; a second-degree polynomial (parabola) has three. In general, GPT-1 is considered the first LLM, which is described by 117 million parameters. Today’s models have up to 700 billion parameters, requiring specialized hardware for their application. Further examples of large language models include OpenAI’s GPT-4.1 or o3, as well as openly available models such as BLOOM, Llama 3, and Mixtral.
Functionality
LLMs do not work directly with words or characters, but with “tokens”—essentially the alphabet of the language model. A token reflects a semantic unit of a word and is the smallest element the model understands. In English, a token is often equated to about ¾ of a word, so on average about 1⅓ tokens are required to form a word. For a language model to process text, it is first broken down into a sequence of tokens and each token is identified by an integer. The original text is thus translated into a chain of numbers. Typically, the vocabulary of modern language models contains about 20,000 to 200,000 different tokens.
Large language models for generative applications are mostly trained to predict the next token based on a given sequence of tokens—so-called Next Token Prediction. Put simply, the goal of training is to optimize the vast number of parameters in the language model so that it can predict the next token for texts from the training corpus as accurately as possible. To train such a large number of parameters, a correspondingly large dataset of texts is required. For high precision, the language model must be capable of understanding context both within sentences and across entire texts. Earlier approaches in computational linguistics, such as Markov chains or neural networks with Long Short-Term Memory (LSTM), do not achieve comparable results.
Sticking with the view of language models as mathematical functions, so far the model appears to compute the next token from a sequence of input tokens. By repeatedly applying the function, always appending the predicted token to the input sequence, it is possible to continue or complete a started text. This is illustrated in the following figure. To enhance readability, input and output texts are shown as plain text rather than tokenized. The model completes the started sentence. Although this appears to work well at first glance, the phenomenon of hallucination also appears here, as the described “FINTURBO Cup” does not exist.

Mental Model for the Model
According to a 2022 survey, computational linguists were divided on whether LLMs truly “understand” natural language in a non-trivial sense, or merely remix and parrot back training texts. It is unclear how language models solve linguistic tasks, and they are often described as black boxes.
The author believes this question is not productive, as it enters deeply philosophical territory. For instance, to answer it, we would first need to define what is meant by “understanding” and to what extent a machine can actually understand anything.
From a practical perspective, it makes sense to use the following mental model for LLMs: Since LLMs are above all trained to predict the next word or token, it is reasonable to say that LLMs merely imitate human language and conversation. It shouldn’t be surprising that such imitation can still be extremely useful for solving tasks. Throughout this article, I will refer back to this perspective to explain the behavior of LLMs in specific examples.
Techniques
The following sections highlight various techniques, all of which are applied in one form or another in today’s AI tools.
Paradigm Shift: Prompt Engineering
Programming has traditionally meant that a computer executes the instructions in program code exactly as written. This can be surprising when, for example, an “obviously” correct algorithm is carried out by the machine differently than a human would expect. Translating abstract ideas into concrete, specific computer instructions is a core part of programming.
Prompt Engineering marks a radical departure from this principle. When language models are used, instructions are no longer executed with mathematical precision. Prompt Engineering refers to the practice of writing instructions—called prompts—to a language model so that it completes a task as reliably and accurately as possible. A prompt is executed by the model in the context of simulated conversation. Small, seemingly insignificant changes to the prompt’s wording can lead to radically different answers. For instance, if a language model’s output must adhere to a specific format to work with traditional software, it is not uncommon to remind the model several times within the prompt about the desired output format, as shown in the following figure.

LLMs tend to invent or guess answers when they do not know the correct response—this is the already described phenomenon of hallucination. Providers of AI services attempt to avoid or reduce hallucination in their products. Because of this tendency, pure language models are not suitable as factual knowledge bases or search engines. Ignorance of this property led to the initial example with the lawyer.
As radical and paradoxical as the departure from mathematical precision in programming may seem, this paradigm shift dramatically increases the range of possible applications. Writing a short textual instruction to an LLM can solve problems that could not be addressed with conventional programming, or only through great effort using traditional computational linguistics techniques. Applications can more quickly adapt to changing requirements simply by changing prompts, whereas retraining a classic computational linguistics model takes significant time.
In-Context Learning
Language models have a limited knowledge base, known as the knowledge cut-off. During training, a large corpus of texts is used. The model cannot know anything about events not included in its training set, for example because they occurred after training was completed. Language models generally cannot access all information from the training dataset as a knowledge base would. The purpose of the dataset is to teach the model language and conversation—not to memorize facts and events.
Since training LLMs is time- and resource-intensive, there are other ways to convey new information to them. A fundamental method is so-called in-context learning, in which, at the start of a conversation with the language model—i.e. after training is finished—the model is given all necessary information for the task as part of the input text. This can include background knowledge required for a task, or examples that demonstrate how the task should be solved (“few-shot learning”). The following figure shows a conversation in which the language model is taught, using examples, how to rephrase sentences.

External Knowledge and Logical Reasoning
The concept of in-context learning can be extended and combined with classic knowledge bases. Information required for answering a question or carrying out a task is added to the conversational context by extracting it from a knowledge base. This technique is called Retrieval Augmented Generation (RAG). RAG applications differ greatly depending on the data source. A RAG application can consult a single document, an encyclopedia like Wikipedia, or all freely available internet content.
Developing the retrieval aspect is essential for a successful RAG system. If the extracted content does not include the information needed to answer the question, the language model cannot provide a meaningful response. RAG is often seen as another method to reduce LLM hallucinations. The following illustrates the workings of a RAG system with an example.

The analogy—that language models merely imitate conversation—points to another limitation that was humorously noted online in the early days of ChatGPT: the lack of logical reasoning ability.
THe following figure illustrates that the language model did not reach the correct logical or mathematical conclusion. The example uses in-context learning to demonstrate what the model is being asked to do. It remains unclear how the model arrived at the answer “27”; the correct answer is 9.
A common technique to guide language models toward logical reasoning is called Chain-of-Thought Prompting (COT prompting), in which the model is encouraged to document and explain intermediate steps. Since of the way the model works, each subsequent step is generated only after preceding intermediates have been “put on paper” and made part of the input. THe following figures shows the same task, this time solved correctly with COT prompting.
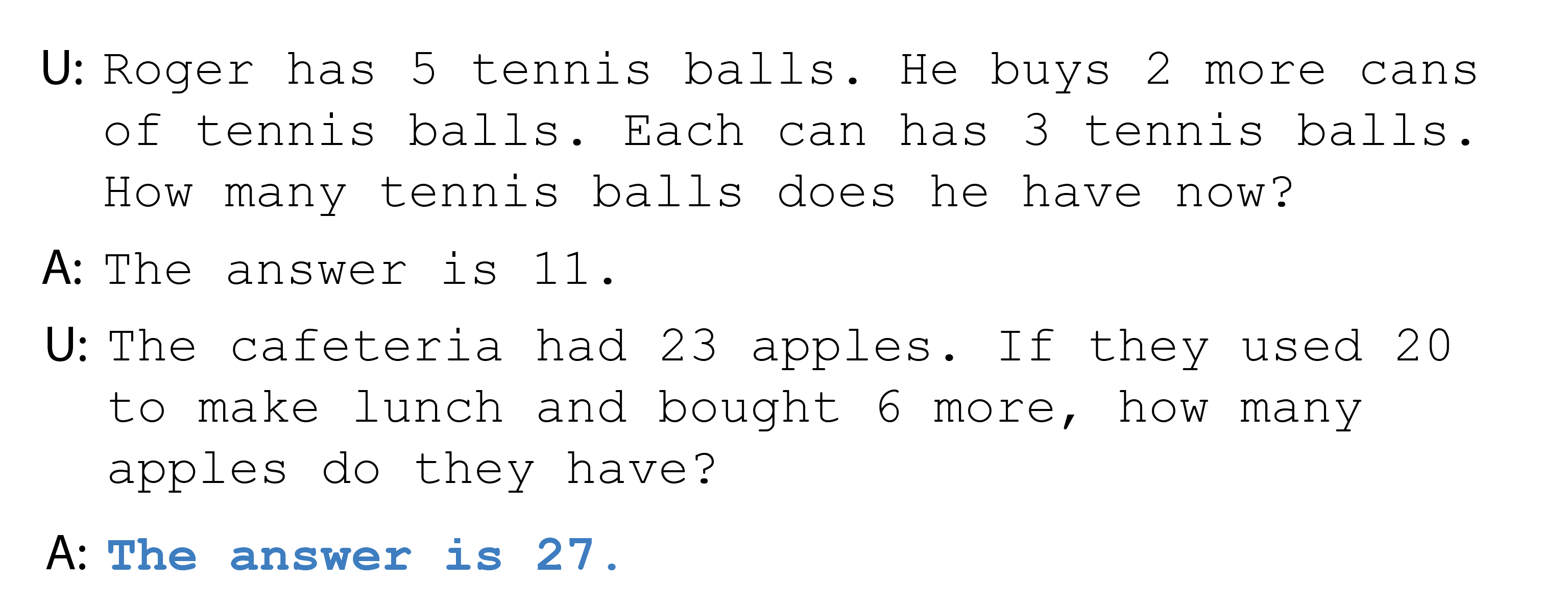

Agents and Fine-Tuning
Innovations in prompt engineering and related techniques allow a language model to be used for a wide range of applications. However, its capabilities are limited to pure text (or audio/image) output. Interaction with external systems requires so-called agents, which can enable complex computations and allow language models to interact with external systems.
Through prompt engineering, a language model is told, in its instruction, what external tools are available for solving a task. This could include a calculator, an external API (to manage emails, appointments, or contacts), a RAG-based search, a free web search, or a coding environment.
Users can assign a task to the language model. The model is instructed to select, from the available tools, the one required to solve the problem. The model communicates the selection and use of tools via a special answer format. Complex systems allow for the use of multiple tools to solve the task step by step.
A language model with internet search and route planner abilities could, for example, handle the request “How long does it take to drive from Vienna to the host venue of the Eurovision Song Contest 2025?” by first using a web search to find where Eurovision will be held in 2025, then using the route planner to calculate the travel time from Vienna to Basel. The answer is about eight hours.
The potential of agent-based applications is virtually limitless in our connected digital world. Today’s language models are often trained on both natural and programming languages, allowing them to generate functional code. In combination with a programming environment, language models can write complex algorithms needed to solve a task and then execute them. The limits of such systems in the future are currently unforeseeable.
All the techniques discussed so far use prompt engineering to influence the work of the language model. To conclude, there is another technique that does not rely on prompt engineering: Through fine-tuning, a pre-trained language model can be customized so that it automatically follows a fixed, predefined instruction. In a way, the model loses its ability to react generically to all prompts. On the other hand, the model doesn’t have to be told its task at the start of every conversation. Fine-tuning is suitable when a language model will be used for a large number of identical tasks. Depending on the fine-tuning method, all the parameters of the model may be adjusted. However, this is often too computationally expensive. Alternatives like PEFT enable fine-tuning by adding or adjusting only a small number of new parameters.
Final Thoughts
Meaningful use of AI in safety sciences requires understanding both the underlying technology and its limitations. By presenting some essential techniques used in today’s AI tools, this article aims to make a contribution here.
The landscape of commercial and open-source language models, and their abilities and methods, is changing rapidly. It is difficult to make predictions about the future of AI. But AI will certainly change the way many industries work, and companies that fail to use AI tools will have a hard time competing. It is therefore all the more important to seize the opportunities that AI provides. To make this easier, this article has highlighted some technical boundaries, to help avoid mistakes in application.
This might also interest you