
When I asked ChatGPT, how to build a RAG-based application, it responded with
“Use a vector database to store the embeddings.”
This article is not a comparison or benchmark of vector databases, but a comparison of a vector database to a non-vector database option: A simple array in memory.
Comparison
Large language models (LLMs) are trained on a large text corpus and excel at mimicking human conversations. However, LLMs alone perform rather poorly at information retrieval tasks. Enter Retrieval Augmented Generation (RAG): Based on the conversation, RAG applications retrieve relevant documents from a given context and prepend them to the input of the LLM. This way, the LLM can generate more relevant responses and the LLM can get knowledge of things that were not in its training dataset. RAG is also seen as a way to reduce hallucinations in LLMs.
The provided context documents are stored by their high-dimensional vector representation. Two points in embedding space with a small distance are considered semantically similar. The challenge is to find the vector with the smallest distance to a given query vector. Since classical database indices and ordering algorithms fail in high-dimensional spaces, specialized vector databases, like Qdrant, are used. They are optimized for high-dimensional vector search. In containerized applications, employing a vector database warrants a separate service, network communication overhead, persistent storage management, credential handling, and more.
However, for small-scale applications, a vector database might be overkill. A simple array in memory might be sufficient. To find the closest vector, the array is iterated and the distance to the query vector is calculated. The following table summarizes some of the differences between a vector database and an array in memory.
| Feature | Vector database | Array in memory |
|---|---|---|
| Complexity | Multiple services with network communication | Simple in-memory array |
| Scaling | Scales to 100 million points and beyond | Scales linearly with the number of documents |
| Updating | Live, concurrent updates | Requires restart |
| Handling metadata | Yes | No |
| Filtering based on metadata | Yes | No |
| Best for | Production and large-scale applications | Prototyping or applications with few documents |
| Query in Python |
|
|
Benchmark
The linear search becomes prohibitively slow for large document collections. How large is “large”? At what point does a vector database become more efficient than an array in memory? Let’s find out. We compare the search time of a vector database to an array in memory. As a vector database, this benchmark uses Qdrant, deployed as a container on my MacBook Pro M1. The array in memory is implemented in Python with NumPy, launched on the same machine. The dependence of the query time on the collection size is illustrated by the following plot.
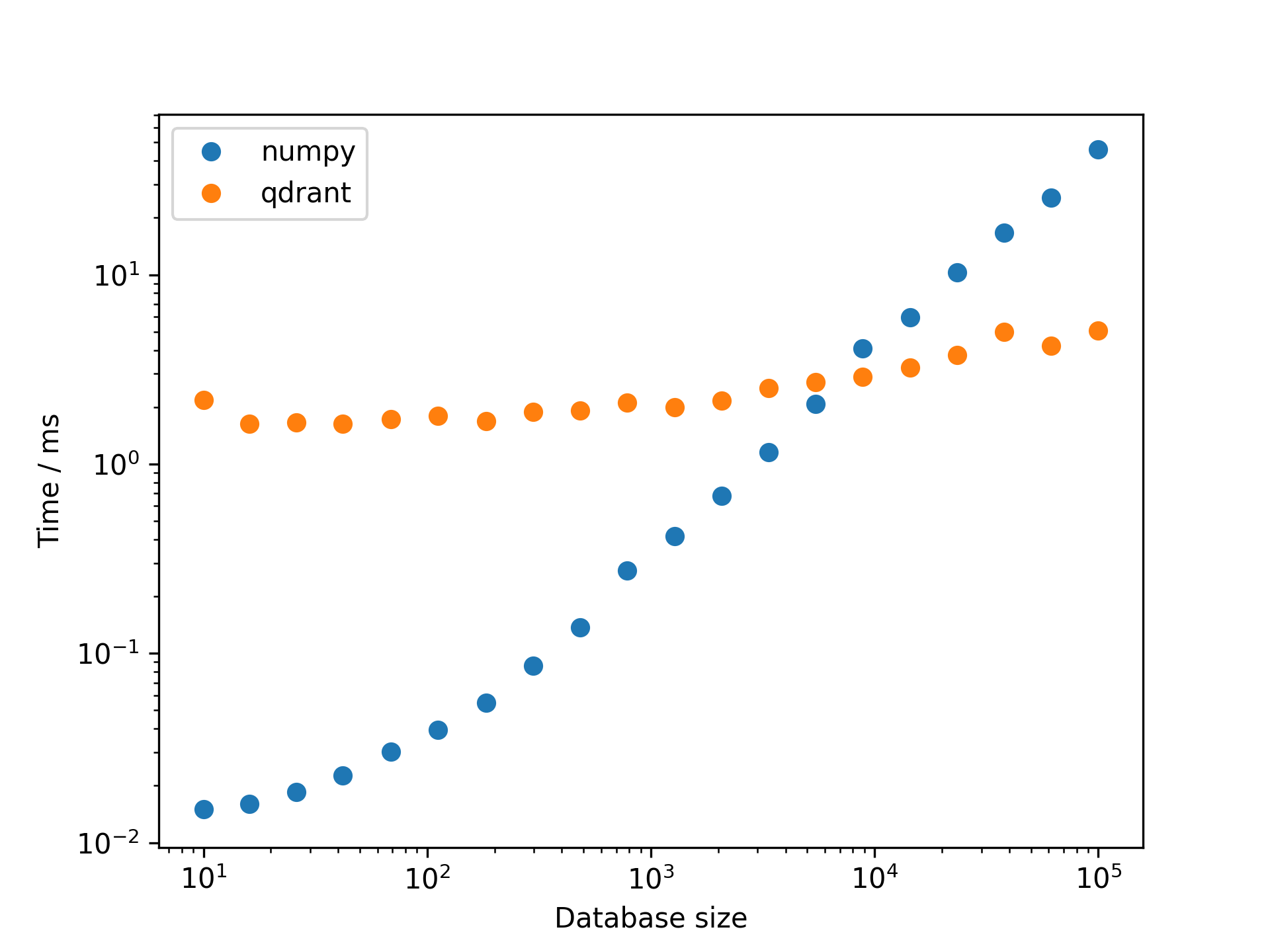
Starting a bit below 10k documents, the vector database is faster than the array in memory. This means, that small RAG-application with, let’s say, 1k documents, a simple array in memory might be sufficient. It depends on the specific requirements of the application, whether the additional complexity of a vector database is justified or, whether the additional features of a vector database are needed.
Is this benchmark representative for all vector databases? No. Is this benchmark reproducible? No. Is this benchmark representative for all applications? No.
Run your own benchmarks to see what works best for your specific use case.
Conclusion
Do you need a vector database for your RAG-application? It depends. Small-scale applications with static data might be fine with an array in memory. For anything else, use trusted vector databases.
This might also interest you