
From data analysis in Jupyter Notebooks to production applications–In this blog post, I’d like to introduce ideas for an AI infrastructure at a reasonable scale, to bridge the gap between doing
- data analysis with artificial intelligence (AI) and machine learning (ML) in a Jupyter Notebook and
- building production applications.
So, let’s start with a quote by Michael Dell:
We are unleashing this super genius power. Everyone is going to have access to this technology […]
I think the key question here is how we define “having access” to the technology and what it entails. Will it be access to a cloud API with a pay-as-you-go subscription model or will it be possible for us, as developers, to build our own applications with our own models, fine-tuned models, and even on our own hardware? At the moment when looking around the internet for resources on how to build an AI application, most resources rely on a cloud API.
I did a highly subjective and biased Google search. Don’t quote me on the numbers as the results are influenced by my search history. I used various combinations of the keywords: tutorial, Python, web app, FastAPI, AI, and LangChain.
- 60 % of the results relied on a cloud API or even closed-weight cloud models,
- 40 % didn’t build an application but rather illustrated a general data science workflow, with exploratory data analysis, while only
- 10 % build a complete application, mostly still limited to a single Python module.
The percentages don’t add up to 100 %, since I’m not dealing with exclusive categories. However, with these numbers, you see a bias towards cloud API models. Most importantly, two things are generally not covered, namely,
- How to use models locally on-premise, and
- How to use your own models, trained specifically for your domain.
I’m not arguing that this information is not available, but it’s almost drowned out by the wealth of information for cloud API models. The purpose of this article is to contribute to counteract this tendency.
Cloud or on-premise
Different people have answered the decision to build an application in the cloud or on-premise differently over the years. To be clear, there is no one true answer. It depends on the contexts, the requirements and the constraints. Both sides have pros and cons. I will list a few benefits for each solution given an AI, ML, and data science context.
Doing it in the cloud
Advantages of building an AI application in the cloud include:
- The cloud offers managed services, which, if used, imply less maintenance work and cost.
- Building an AI application in the cloud means you get access to closed-weight models that are not accessible otherwise, like GPT4o.
- In the cloud you pay as you go, so during times when you don’t use services or only to a small extent in terms of volume and time, you pay less.
- The initial cost to get started is small.
- Modern cloud providers allow you and encourage you to define the entire infrastructure as code which has the advantage of being archivable and versionable.
- If developed appropriately, applications in the cloud have unprecedented ability to scale on demand.
Doing it on-premise
- Building applications on-premise doesn’t come with a vendor lock-in. You can switch software and hardware anytime.
- There is no data lock-in. If data is stored locally on hard disks, it’s easy to replicate, copy to other media, or transport the data. In contrast in the cloud, it can become very costly to transfer your own data out from the cloud.
- For private projects, in academia, or in a company, you could reuse existing hardware resources.
- Initially, maintenance is more expensive, however, there are economies of scale. You need one system administrator to maintain one server, but you don’t need 100 system administrators to maintain 100 servers.
- By storing data on-premise you can enforce very strict data governance and data privacy regulations.
Both approaches have their benefits. In this post, I will focus on on-premise setups, however, it is possible to build the same infrastructure using cloud resources and services.
The goal of the infrastructure
The target domain of the infrastructure is
- Personal projects,
- Projects in academia, and
- Products in businesses.
Therefore the infrastructure is applicable in a very wide range of domains. The requirements change depending on the scale and domain and the ideas presented in this post, don’t necessarily apply to all domains equally. For personal projects, it might be sufficient to select a subset of components and features from the infrastructure, while for large commercial applications, scaling becomes an important aspect and more pieces of the infrastructure need to be in place.
The infrastructure is evaluated against four metrics, namely,
- Reproducibility: How easy is it so that other people can rerun inference requests or a study and obtain the same results?
- Rapid development: Can applications be developed quickly by relying on the infrastructure?
- Reasonably scaleable: Does the setup scale to a reasonable scale? I mean by that will be defined later.
- Efficient use of resources: Can we efficiently use the available and pre-existing hardware resources?
After having set out these metrics, let’s see what the actual architecture of the infrastructure looks like.
Layered architecture
The key insight is that we need a layered architecture. If you want a single takeway from this article, that’s it. To be honest, I didn’t invent layered architectures. Layered architectures make sense for classic software projects and I argue that they make a lot of sense for AI infrastructure. The components of the infrastructure are split into three distinct layers: the models, a gateway, and the applications. Let’s start with models.
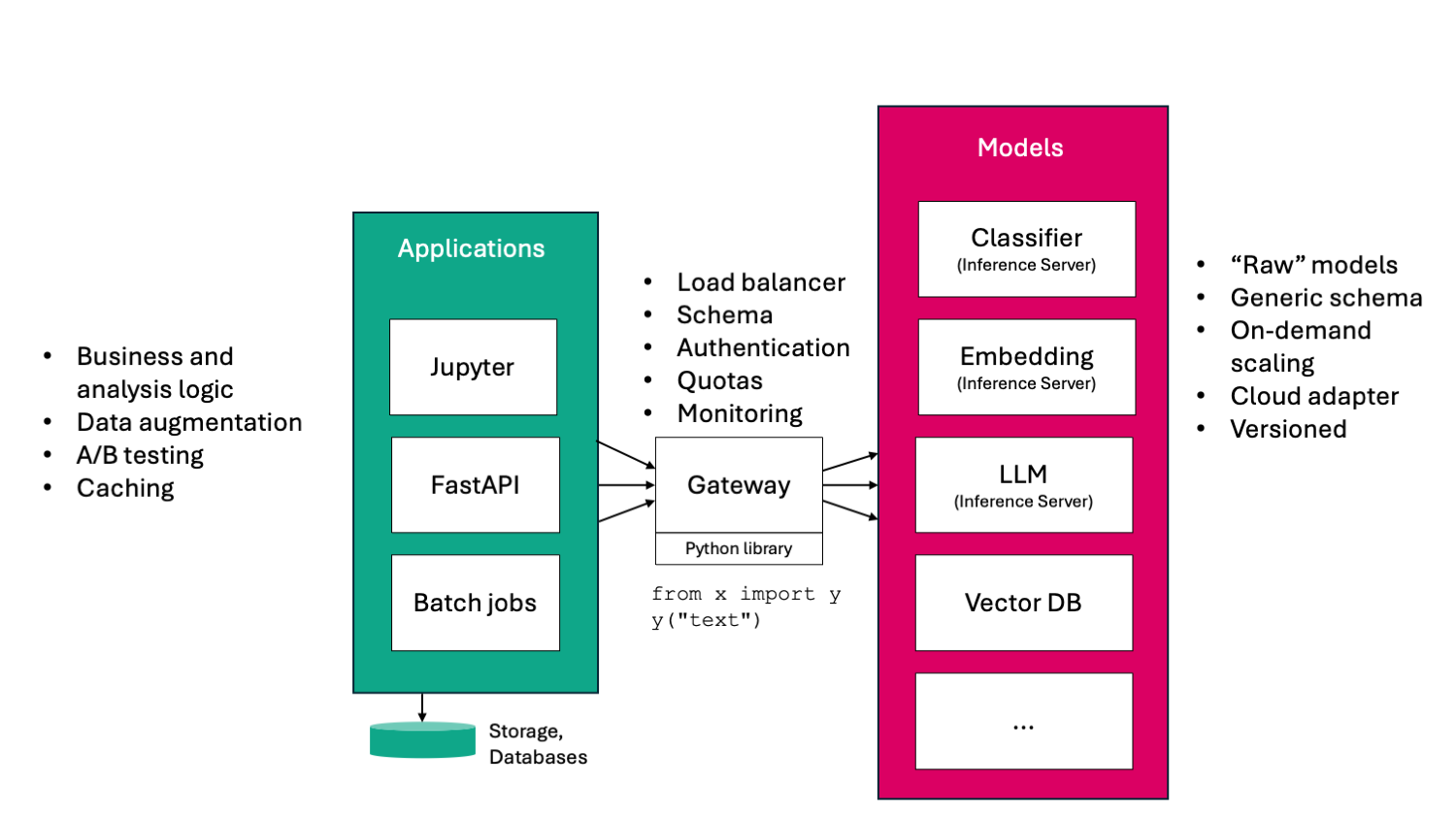
Model layer
This layer comprises the raw AI models. When I speak about models, I mean to include a wide range of models. For example, you might be working with
- Classifiers or regressors, let it be for text, images, sound, or application-specific measurement points,
- Embedding models, again, for text, images, sound, graph nodes, or more complex application-specific structures,
- Large language models ranging from smallish models with 100s of millions of weights to gigantic models with 100s of billions of weights–whatever is possible with your hardware,
- Vector databases, as they are trained, in a sense, when points are added to the collection and we can run inference by doing approximate nearest neighbor lookups, and
- Anything else that you might fancy. Nobody is stopping you from adding an adaptor to cloud API models at this stage and building a hybrid architecture.
The models at this stage are the raw model weights packaged together with inference servers like mlserver, or Huggingface text inference server. The inference servers usually have a generic API schema, which can be used for a very wide range of models, but on the other hand, get can be difficult to use: With a generic schema, there is no built-in documentation of what inputs your model expects. You might be sending the inputs in the wrong format. And, similarity, you might parse and use the return values incorrectly.
To achieve scalability and on-demand scalability, it is beneficial to deploy the models as containers. By following general DevOps practices at this stage, we also ensure that the models are versioned and deployed properly and consistently.
Most of the software that’s needed to build the model layer is off-the-shelf.
Gateway
The gateway is a central point in the architecture that every request to the AI models needs to traverse. This doesn’t imply it is a single point of failure as the gateway API can be set up in high-availability mode. The gateway acts as a load balancer to the on-demand scaled models. Because of its location in the architecture, the gateway can impose a schema. Requests to each model need to comply with the input schema. Clients of the gateway can use common auto-documentation tools to learn the input and output schema, e.g., OpenAPI and Swagger, gRPC service definitions, etc.
The gateway is also a good place to add authentication and authorization. Maybe not every user or every application should have access to all models. Similarly, we can add quotas. One user or one application should not be able to consume all available resources and cause a denial of service for everyone else. This is more important for business domains with a multi-user environment. Additionally, the gateway is a good place to add monitoring to see how models are used and if someone might abuse the service. This becomes much more important as soon as there are large language models in the model layer.
The gateway is custom code. There are projects and initiatives to have a generic open-source solution for the gateway, but in my view, a custom solution offers more benefits.
Finally, in my experience, it pays off to invest time when developing the gateway, to build a small Python library that acts as an adaptor or proxy for the models. Our goal should be to make using models as easy as it gets. Popular cloud API providers, like OpenAI, show how it can and should be done. For example, using a model should be as easy as
from x import y
y("my input text")
where x is our custom library to access the gateway and y is one of our models.
We will later see how this affects the development time of applications. It also
helps to focus on the business part while building applications and abstracting
the complicated AI models into a simple function call.
Applications
Lastly, let’s look at the applications layer. By applications here, I mean applications in a very broad sense. This can be
- One-off analysis in a Jupyter Notebook,
- Showcase examples in a Jupyter Notebook,
- A FastAPI API that’s released as a service or the backend of a web frontend,
- Large-scale batch jobs to process bulk data and compile an analysis report, and
- Anything else that needs AI model inferences to work.
The application layer is the correct place to implement any application-specific business or analysis logic. It’s also the right place to join inference results with additional data sources like databases or files. Any CPU and IO-intensive data transformation, data filtering, data augmentation, or data aggregation should take place in the application layer and not in the model layer.
The application layer is also the ideal place to do A/B testing. A/B testing sounds like it’s only relevant in the business domain where we collect feedback from actual user traffic to test one approach or model (A) against another model (B). However, this is in principle the same as a benchmark in an academic domain: Which model is more sensitive to the quantity that I want to extract and measure from a dataset?
If necessary, the application layer is also the place to implement caching. Caching can imply storing inference responses or the result after applying additional business and analysis logic. It depends on what is the bottleneck. If it is pure inference time, then caching model results might work. If the business logic and data transformations are the bottleneck, then maybe caching the final result is the answer.
Evaluation
After having introduced and explained the infrastructure, it’s now time to evaluate how the infrastructure fosters reproducibility, rapid development, reasonable scalability, and efficient use of resources. Let’s start with reproducibility.
Reproducibility
What do I mean by reproducibility in this context? The infrastructure should give people the opportunity to repeat a study, and analysis, or any inference request and obtain the same result. Managing the input data, however, is beyond the scope of the AI infrastructure. Joel Grus gave a famous talk at JupyterCon 2018 titled I don’t like notebooks. If you don’t know the talk, go search for the recording, it’s very entertaining. One of the messages from the talk could be summarised by
If your output is science, you need reproducibility through best software engineering practices.
How do best software engineering practices help us in this case?
The model layer promotes the use of containerized models that are deployed with deployment pipelines. If we make the step and view models as testable product releases, we gain a lot in terms of reproducibility. The architecture of the infrastructure is very welcoming if we follow this principle. When adhering to that and treating models as testable product releases, we get a few things for free that help us to ensure reproducibility
- Models are automatically versioned,
- Models go through a proper deployment process.
With these two benefits, we eliminate a whole range of problems, i.e., the
equivalent of “works on my machine” in the AI world–The model doesn’t run on
your machine anymore. Deployments are tracked and in the best case can be easily reverted.
This also eliminates the need to copy model weights manually from one machine to
another with scp. We also ensure that any inference code that’s wrapped around the
model, including any preprocessing or post-processing, is applied consistently.
This includes for example tokenization of input text or shifting and
scaling input variables. Additionally, we ensure that the environment and the
dependencies of our model are consistent and available at runtime.
Rapid development
Consider the following code example of a FastAPI endpoint that accepts an input string, computes a semantic embedding, and searches for similar documents in a vector database with the qdrant client. You can find similar snippets all over the internet.
app = FastAPI()
embeddigns = HuggingFaceEmbeddigns(model_name="mymodel")
qdrant_client = QdrantClient("localhost:6333")
@app.post("/serach")
def serach(query: str) -> list[str]:
vector = embeddings.embed_query(query)
points = qdrant_client.search("mdpi", ("mymodel", vector))
return (point.payload["title"] for point in points)
This might look like a quick and sensible solution, however, if your coding style is anything like mine, you change the file, save it, and retest the code many, many times. In my view, this iteration loop is vital during development. This is where it gets problematic when working with AI models. Every time we save the file and reload the API, we need to reload the embedding model into memory. This might be fine for small models with millions of weights, however, already a few seconds of delay can be annoying and slow down your workflow. As models tend to become larger, it takes minutes or up to an hour to load it into memory. At this point, any iterative development workflow should be considered broken. So how does the infrastructure help us here?
The model and the application code are decoupled. We have our custom Python
library x that we can use to send inference requests to the gateway. The library
has a minimal footprint and reloading this library should not entail a
noticeable delay. Furthermore, our library to access the gateway has minimal
dependents, so we require only a minimal setup and boilerplate code to use a model
(from x import y). Using the model becomes as easy as it gets.
You might argue that treating models as product releases slows down the development cycle. I agree. It might be tempting to only release models once they have reached a certain level of “maturity” by passing some checks and benchmarks. However, speaking with reproducibility in mind, if benchmarks are run without properly releasing the model, are you sure that you can reproduce the exact same benchmark with the same model? If the answer is no, then the benchmark is meaningless. In my view, the additional investment of treating every model as a testable release pays off.
Reasonably scaleable
What is reasonably scalable? To give you a number: I mean working with datasets that are terabytes in size. This could be a few terabytes or 10s of terabytes. As a comparison in the domain of NLP. The whole compressed English Wikipedia dump as of 2024 is around 30 GB–that’s multiple orders of magnitude smaller. I argue that terabytes are actually sufficient for most applications.
How does the infrastructure help us in that regard? The model layer promotes dockerized models. With a container scheduler (this can be Kubernetes or something more simple) and the load balancer in the gateway, we achieve already a great degree of scalability and can even scale on demand.
Efficient use of resources
When I was working at CERN, I was lucky to have access to the Worldwide LHC computing grid–a large-scale collaboration of data centers to bulk process 100s of petabytes of data. Therefore, I think it is very common, especially in academia, that there are already existing hardware resources: compute power, data storage, and GPU. You might have a GPU from the previous research project in the group. At least during my time in academia, I have seen requests for GPU resources, but I have not seen a grant application that mentioned funds for computing power from a private cloud provider.
If we pool resources from multiple projects together, we can smooth load peaks. It’s less likely that all our applications and models experience a spike in the number of requests at the same time. So if only one application or model is in demand at one point in time, that application or model can scale to the entire available hardware. So, with the infrastructure we can incorporate heterogeneous resources and make use of dedicated GPU resources. We can even share GPUs across multiple projects.
Due to the separation of CPU and IO-intensive tasks in the application layer from the GPU intensive inference of the models, we make sure that each type of resource is used in the best way. It doesn’t make sense to run CPU-intensive tasks on an expensive server with a GPU such that inference speed and throughput degrades due to the CPU load.
What’s more
Networking
The key idea for the AI infrastructure is a layered approach with minimal coupling between the application layer and the model layer. This all depends on fast network communication. The choice of communication protocol has a large impact. Two very common choices are HTTP+JSON (often incorrectly referred to as “REST”), and https://grpc.io/. Both have their individual strengths and advantages.
JSON is a verbose format. It’s manually editable and easily readable. There is almost universal support for the serialization and deserialization of JSON. Practically every programming language offers libraries to send HTTP requests. However, the verbose nature of the format becomes a disadvantage for the AI infrastructure. Requests to and responses from the ML models often consist of a high-dimension vector of floating point numbers (embedding vectors, classification results). In JSON, this needs to be converted to strings and parsed again into floats. This conversion introduces a CPU overhead. The string representation of a 4-byte floating point number requires about 10 bytes as a string, and therefore, requires more network bandwidth.
gRPC is much more concise due to its binary nature. Development with gRPC requires additional tooling and frameworks, however, generally, the support for gRPC is good. Is the additional development cost justified by a noticeable improvement in inference speed? Well, let’s measure.
The following benchmark computes text embeddings using a BERT-like model. The parameter on the \(x\)-axis is the number of parallel text inputs processed as a single batch by the model. The \(y\)-axis illustrates the average processing time required per text input. Using larger batches usually improves the per-item speed as any overhead associated with the request as a whole occurs only once per request and is shared by all items. Note that both axes are in a logarithmic scale. The benchmark is repeated four times under different conditions: (REST vs. gRPC) × (CPU vs. GPU)
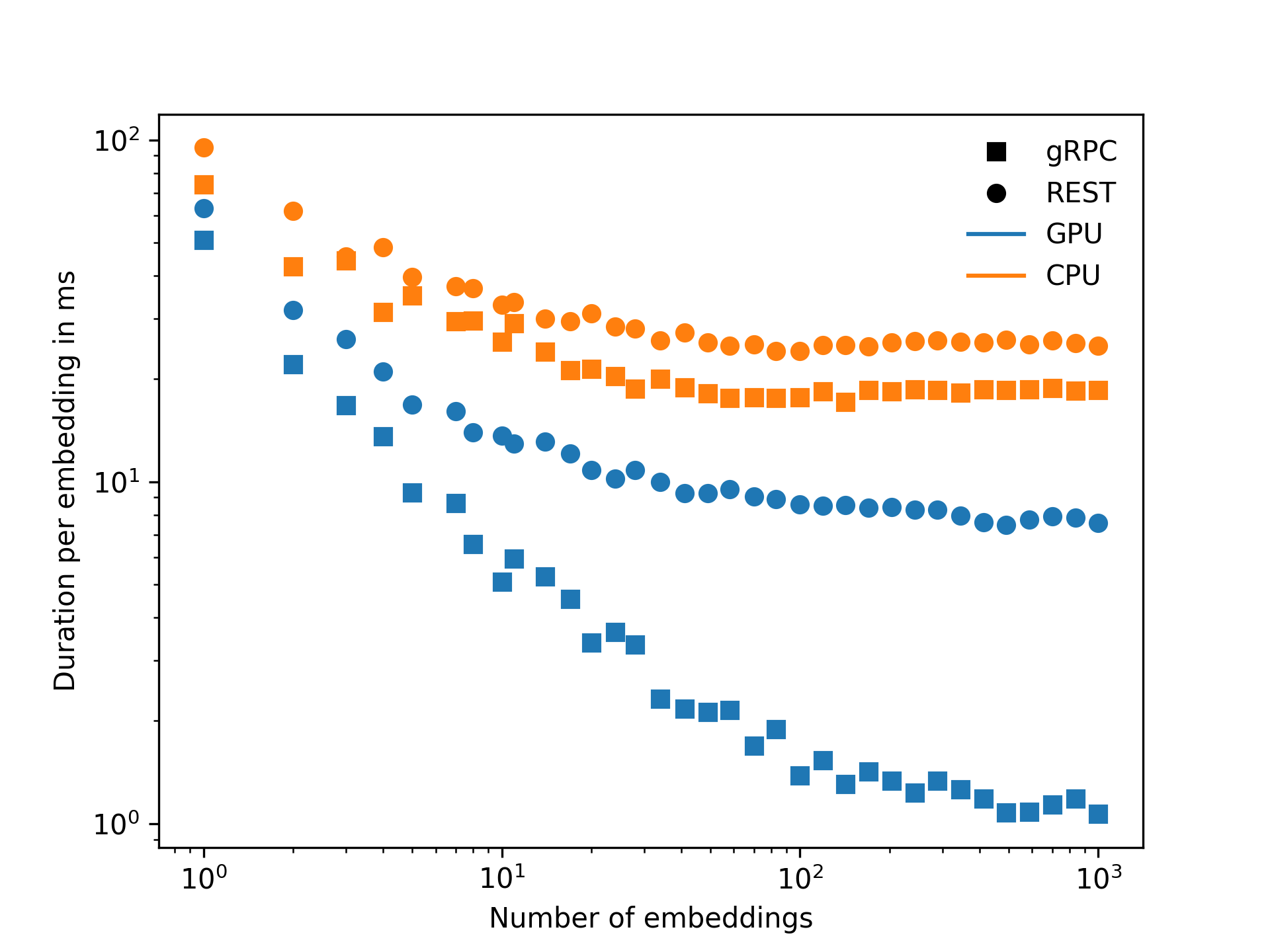
Let’s focus on the CPU case (in orange) first. We see an increase in speed until around a batch size of 50 for both communication protocols. After that, it flattens out with a processing time of 20 ms for gRPC and 30 ms for REST. The result can be understood that we hit the limitation of the CPU for AI inference. The CPU cannot compute more embeddings in parallel. Additional reductions in the overhead are negligible compared to the processing time required by the CPU. In other words, the CPU becomes the bottleneck above a batch size of 50. gRPC is around 30 % faster in that regime.
Now, let’s switch to the case where inference is done on a GPU (in blue). One thing to notice is that inference times on the GPU are much faster than on the CPU, as expected. For the REST case, we seem to approach another plateau after a batch size of a few hundred. For gRPC, inference times improve even beyond the batch size of 1000 and gRPC ends up being 10x faster. This performance difference can be understood as a JSON bottleneck. The GPU could run more parallel inference, but we cannot encode, decode, and send data fast enough.
The benchmark nicely demonstrates the power of gRPC in this context and in my view justifies the additional development time to use gRPC as a communication protocol between the application, the gateway, and the model layer for CPU-based and GPU-based inference. If the gRPC client is embedded in the custom library for the gateway, the communication protocol is opaque to the applicant.
Bigger picture — MLOps
AI and ML projects are difficult. In contrast to classical software projects, we need to track changes in our
- Code,
- Data, and
- Model (weights).
The established practice to manage these changes and iterate based a feedback is called MLOps, in my view, the ML equivalent of DevOps. A good description called Continuous Delivery for Machine Learning can be found on Martin Fowler’s block. The same practices are now transferred to even more domains and referred to as AIOps and PromptOps. How does the AI infrastructure fit into the picture?
The infrastructure described in this article is concerned with the second half of the MLOps live cycle, namely, the productionization of the model, handling application code, releasing the model and monitoring the model to production. Other very important aspects, like handling the training data set or training the model are beyond the scope of this production-centric infrastructure.
Conclusion
What’s next? The key idea is to build the AI infrastructure in layers to reduce coupling between applications and models from an operational point of view. The idea is not new or unique for AI, but brings enormous benefits, such as,
- Versioned model releases,
- Minimal setup to use model,
- Scalable to Terabytes of data, and
- Use of specialized GPU resources.
The infrastructure is used at MDPI for all its internal and external-facing AI products.
This article is based on a talk at the EuroSciPy 2024 conference in Szczecin, to be presented on August 28, 2024. Stay tuned.
This might also interest you