
This article is for everybody that knows the difference between big-endian and little-endian but frequently confuses the two terms. If you are like me, you might think
“Big-endians end with the big part of the number (i.e., the most significant byte, MSB).”
This is wrong. So, please forget that notion right away. This article shows the correct mental model for big- and little-endians.
The terms of big- and little-endian originate from Jonathan Swift’s book Gulliver’s Travels. The book describes types of people:
- Big-endians who breaks the shell of a boiled egg from the big end
- Little-endians who breaks the shell of a boiled egg from the little end
Let’s visualize this image and build the analogy by considering the number
1729
or 0x06c1 in hexadecimal. So our example number expressed as a short-int consists of two bytes, 0x06
and 0xc1. The question of endianness is the order in which we want to store
these two bytes to represent the number 1729.
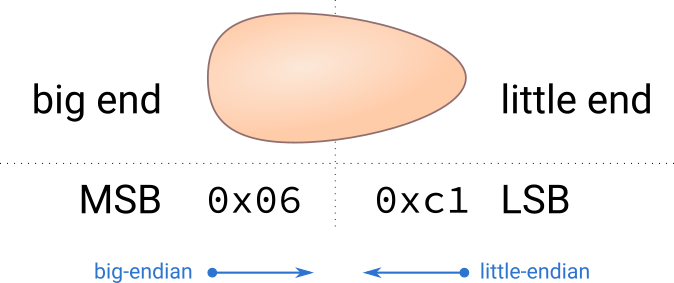
From the image, we see that
- a big-endian means we write the number starting from the big end, i.e.,
0x06 0xc1, whereas - a little-endian means we write the number starting from the little end,
i.e.,
0xc1 0x06.
With this model in mind, it should be easier to keep the two terms apart.
This might also interest you